Heathkit HERO 2000 (ET-19) · Volume 7
Speech — Direct Text-to-Speech
7.1 What this volume covers
Speech is the one subsystem where the HERO 2000’s advance over its predecessors
is most easily heard rather than measured. The HERO 1 and the HERO Jr both spoke,
but they spoke the hard way: a program had to hand the synthesizer a stream of
phoneme codes — the elementary sounds of English, hand-assembled in the right
order — before the robot would say a word (covered in the HERO 1 and HERO Jr
speech volumes). The HERO 2000 inverts that burden. Its headline speech feature is
direct text-to-speech: a program hands the robot ordinary text and it speaks,
with no phoneme hand-coding required (HERO 2000 spec sheet, hero.dsavage.net).
This volume describes that advance and draws the contrast with the Votrax-based HERO 1/Jr sharply, because the contrast is the point. It then takes up the one genuine snag in the record — the identity of the speech chip, which the factory spec sheet names as the SSI 263A but which several secondary sources call the “SPA-256” — and presents both readings without forcing a resolution. It lays out the three documented speech modes (text-to-speech, phoneme, and sound effects) the spec sheet attributes to the part, and it explains, at a high level and without inventing the HERO 2000’s specific algorithm, how direct text-to-speech necessarily works: a text-to-phoneme conversion stage feeding a phoneme synthesizer.
As elsewhere in this deep dive, the HERO-2000-specific facts — the chip name, the
three modes, the direct-text-to-speech capability — are gated to the HERO 2000
record (the transcribed factory spec sheet at hero.dsavage.net, the deepest
technical anchor available; cross-checked against theoldrobots.com and
robotworkshop.com). The general behaviour of a phoneme-based speech LSI — what
such a part is and how text becomes phonemes becomes sound — describes the class
of part, and is attributed to SSI 263 documentation and to the general
principle of text-to-speech rather than asserted as a documented HERO 2000
internal.
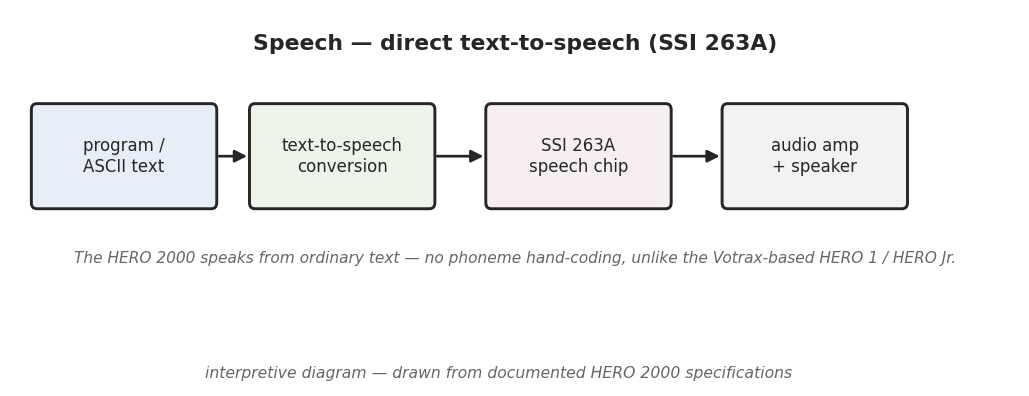
7.2 The headline advance — speaking from text, not phonemes
The single most important fact about the HERO 2000’s voice is what a programmer does not have to do. On the HERO 1 and the HERO Jr, both built on the Votrax SC-01 phoneme synthesizer, making the robot talk meant working in phonemes: software presented the chip one small numeric phoneme code at a time, and a word was a hand-built list of those codes in sequence (HERO 1 and HERO Jr speech volumes; Votrax SC-01 documentation). The chip rendered exactly the phonemes it was given, so the burden of spelling English into its elementary sounds — deciding that “robot” is rendered as the sequence of sounds it is, and getting the order and the stress right — fell on the person writing the program.
The HERO 2000 moves that burden into the machine. The factory spec sheet documents the robot’s speech subsystem as offering direct text-to-speech: a program supplies ordinary text and the robot converts it to speech itself, with no phoneme hand-coding required (HERO 2000 spec sheet). For a programmer, the difference is the difference between writing
say “hello”
and writing out the phoneme sequence that the word “hello” decomposes into. The
first is what the HERO 2000 documents; the second is what the Votrax-based robots
required. This is the same kind of step a desktop computer of the era took when it
gained a PRINT-like speech call instead of a poke-the-synthesizer-register
routine: the capability did not change what the loudspeaker could physically
produce, but it moved a large, fiddly translation job from the human to the system.
Two qualifications keep this honest. First, “no phoneme hand-coding required” does not mean the phonemes have gone away — they have moved: direct text-to-speech is built on top of a phoneme synthesizer, so the conversion from text to phonemes still happens, but the system does it. Second, the HERO 2000 did not abandon the lower level — the spec sheet documents a phoneme mode as well (below), so a programmer who wants the fine control of working in phonemes directly still has it. The advance is that text-to-speech is the default, available path, not the only path.
This is the feature the overview (Vol 1) flagged as one of the three that most separate the HERO 2000 from its siblings, alongside the multiprocessor architecture (Vol 2) and the 360-degree sensing ring (Vol 5). It is also of a piece with the machine’s purpose: an advanced educational and automation trainer (Vol 1) whose users were writing real programs in HERO 2000 BASIC and assembly (Vol 8) benefits far more from a one-line speech call than a living-room robot would, and the HERO 2000’s design spends its larger ROM and its dedicated processors partly on exactly that kind of convenience.
7.3 The chip in the record — SSI 263A versus “SPA-256”
There is one place where the HERO 2000 speech record genuinely disagrees with itself, and this volume neither hides it nor pretends to settle it: the identity of the speech chip.
7.3.1 What the spec sheet says
The transcribed factory spec sheet at hero.dsavage.net — the deepest and most
chip-specific source available for the HERO 2000, treated throughout this deep dive
as the near-primary technical anchor — names the speech device as the SSI 263A
and credits it with three capabilities: text-to-speech, phoneme, and sound effects
(HERO 2000 spec sheet). This is the most technically specific statement in the record,
and it is internally coherent: the SSI 263 is a real, identifiable speech-synthesizer
LSI of the period (below), and the “A” suffix is a revision marker of the kind chip
makers routinely use.
7.3.2 The “SPA-256” reading
Several secondary sources, by contrast, refer to the HERO 2000’s speech part as the “SPA-256” rather than the SSI 263A (secondary sources; cross-referenced against the spec sheet). The designation does not match any standard speech-LSI part number in the way “SSI 263” does, and it is reported here as it appears in those secondaries — a name in the record — rather than endorsed.
7.3.3 The likely resolution — flagged, not asserted
The most economical way to reconcile the two is that they are naming different things: the SSI 263A is the chip — the silicon device that actually synthesizes the speech — while “SPA-256” is most plausibly a Heathkit board, module, or accessory designation for the speech subsystem the chip sits on, in the same family as the ET-/RT- and card-level part numbers Heathkit assigned to its own assemblies. A vendor naming its speech board one thing while the chip on that board carries the manufacturer’s own number would explain how both names attach to the same capability without contradiction.
That reading is offered as the likely explanation, and no more. The gated record does not contain a document that states “the SPA-256 board carries an SSI 263A,” so this volume does not assert the chip-versus-board resolution as settled. What it asserts is narrower and is gated cleanly: at the chip level, the speech device is the SSI 263A — per the HERO 2000 spec sheet. The “SPA-256” name is recorded alongside it as the alternative designation in the secondary literature, with the chip-versus-board reconciliation flagged as the probable but unconfirmed account. The authoritative resolution is a question for the factory ET-19 Technical Manual, which a reader should consult for the definitive parts list.
7.4 What the SSI 263 is, in brief
The chip-level claim above is gated to the spec sheet; the following describes the class of part the SSI 263 belongs to, and is attributed to SSI 263 documentation — it describes what such a device is, not an undocumented claim about the HERO 2000’s particular board.
The SSI 263 is a single-chip phoneme-based speech synthesizer — a text-to-speech / phoneme LSI of the same broad family as the Votrax SC-01 used in the earlier HEROs, and a contemporary of it (SSI 263 documentation). Like the SC-01, it synthesizes speech rather than replaying stored recordings: it builds spoken sound from phonemes, the elementary sounds of speech, so that the right phonemes in the right order produce any word — an open-ended vocabulary, rather than a fixed list of pre-recorded clips (SSI 263 documentation; and compare the SC-01 in the HERO 1/Jr speech volumes). This is what makes a robot able to say arbitrary text rather than a canned phrase set.
The mechanism is formant synthesis: human speech sounds are shaped by formants — the resonant peaks the vocal tract imposes on the sound from the vocal cords — and a formant synthesizer generates sound from an excitation source passed through filters tuned to each phoneme’s formant frequencies, gliding between successive phonemes’ targets so that a string of discrete codes runs together into connected speech (SSI 263 documentation; the same principle described for the SC-01 in the HERO 1/Jr speech volumes). Beyond selecting phonemes, a part of this class typically exposes some control over pitch (inflection), amplitude, and rate, giving speech a measure of intonation rather than a dead monotone (SSI 263 documentation). Exactly which of these controls the HERO 2000’s firmware drives, and how, is a property of that firmware and is not enumerated in the gated record — this volume describes the part’s general capability and does not reconstruct the HERO 2000’s specific use of it.
The relevant point for the HERO 2000 is that a phoneme synthesizer of this kind is the right foundation for text-to-speech: because it already turns phoneme codes into arbitrary speech, all that direct text-to-speech adds in front of it is a stage that turns text into those phoneme codes. That is the subject of the last section.
7.5 The three documented speech modes
The HERO 2000 spec sheet credits the speech subsystem with three modes, and they correspond exactly to the three ways one can drive a phoneme synthesizer (HERO 2000 spec sheet):
-
Text-to-speech. The headline mode. A program supplies ordinary text and the subsystem converts it to speech, doing the text-to-phoneme translation itself (HERO 2000 spec sheet). This is the mode that distinguishes the HERO 2000 from the Votrax-based HEROs and the one Figure 1 traces.
-
Phoneme. A program supplies phoneme codes directly, bypassing the text-to-phoneme stage and driving the synthesizer at the level the HERO 1 and HERO Jr always worked at (HERO 2000 spec sheet). This is the escape hatch for cases where the automatic text-to-speech conversion mispronounces a word or cannot reach a wanted sound — the programmer drops down a level and spells the phonemes themselves, exactly as on the earlier robots, but now by choice rather than necessity.
-
Sound effects. The subsystem can also produce sound effects rather than speech (HERO 2000 spec sheet) — non-speech audio output. The gated record names the mode but does not enumerate the specific effects available; their catalogue is a property of the firmware and is left unclaimed here rather than invented. That a formant synthesizer can be driven to make non-speech tones and noises is consistent with the class of part (its excitation sources and filters are not restricted to speech), but the HERO 2000’s particular effect set is a Technical/Programming Manual detail.
The three modes are best read as three entry points into the same synthesizer at different levels: text on top, phonemes in the middle, raw sound-effect generation alongside. The headline advance — direct text-to-speech — is the topmost of those entry points being available at all.
7.6 How direct text-to-speech works, at a high level
It is worth being precise about what “direct text-to-speech” must involve, while being equally careful not to claim the HERO 2000’s specific algorithm, which the gated record does not give. The general principle is well understood and is stated here as such; the HERO 2000’s particular implementation is a matter for the ET-19 Technical and Programming Manuals.
Any text-to-speech system built on a phoneme synthesizer has to bridge a gap. The synthesizer’s input is phoneme codes; the program’s input is text — letters, not sounds. The bridge is a text-to-phoneme conversion stage: a step that reads the text and produces the phoneme stream that text should be pronounced as (the general principle of text-to-speech; and see Figure 1). In English this is a non-trivial job — spelling and pronunciation correspond loosely, so the conversion involves pronunciation rules and exceptions — which is exactly why moving it off the programmer and into the system is the advance this volume opened with.
So the HERO 2000’s direct text-to-speech path, in its documented outline, is a two-stage pipeline:
- Text in. A program supplies a string of ordinary text to the speech subsystem (HERO 2000 spec sheet, “text-to-speech” mode).
- Text-to-phoneme conversion. That text is converted into the corresponding stream of phoneme codes (general text-to-speech principle; the stage that distinguishes text-to-speech mode from the bare phoneme mode).
- Phoneme synthesis. The phoneme stream drives the synthesizer — the SSI 263A per the spec sheet — which renders it as continuous spoken audio out through the robot’s speaker (HERO 2000 spec sheet; SSI 263 documentation for the synthesis step).
The phoneme mode (above) is simply this same pipeline with stage 2 — and the text input of stage 1 — removed: the program supplies the phoneme codes of stage 3 itself. That is why the two modes sit so naturally together, and it is the cleanest way to see what “direct text-to-speech” actually buys: stage 2, the text-to-phoneme conversion, done by the machine.
What this volume deliberately does not do is reconstruct how the HERO 2000 performs stage 2 — whether by a rule set, a dictionary, a combination, where that code lives, or how large it is. None of that is in the gated record, and inventing it would violate the no-fabrication rule (protocol §7). What is documented is the existence of the capability and the shape of the pipeline; the algorithm itself is left to the factory manuals.
7.7 Where it sat — and where to read on
The HERO 2000’s speech subsystem is the clearest single illustration of the machine’s generational character. The HERO 1 and HERO Jr made a robot talk by making the programmer think in phonemes; the HERO 2000 made the robot talk by making it think in phonemes for you, and left the phoneme level available for when you wanted it. That is the same move the rest of the machine makes — the multiprocessor architecture (Vol 2) that offloads real-time work to dedicated slaves, the BASIC in ROM (Vol 8) that spares the user the monitor, the 360-degree sensing ring (Vol 5) that maps the room without turning — convenience and capability bought with the larger, costlier, later-generation design the overview (Vol 1) placed at the top and the end of the HERO line.
The speech subsystem connects outward to two other volumes. Where the speech work sits among the HERO 2000’s processors — master 8088 or a slave — is an architecture question this volume leaves open, as the gated record does (Vol 2). As a thing a program drives, speech is reached through the programming model: the speech call a program makes, in HERO 2000 BASIC or assembly, is part of Vol 8, whose exact syntax is deferred to the Programming Manual. Every hard speech fact here is collected, with the rest of the machine’s numbers and its flagged conflicts, in the Vol 10 cheatsheet — including the SSI 263A / “SPA-256” chip conflict, shown there as a conflict rather than a settled fact.
Sources
- HERO 2000 spec sheet (
hero.dsavage.net,/robots/Hero2/Hero2_Specs.html) — the transcribed factory spec sheet and the deepest technical anchor for the HERO 2000. Names the speech chip as the SSI 263A and documents its three modes — text-to-speech, phoneme, and sound effects — and the direct-text-to-speech capability. The chip-level claim and the three-mode list in this volume are gated to this source. - theoldrobots.com (
hero2k.html) and robotworkshop.com — secondary specs and photos; among the secondaries that refer to the speech part as the “SPA-256” rather than the SSI 263A (the conflict flagged in-text). Reported as the alternative designation in the record; not endorsed over the spec sheet at the chip level. - SSI 263 documentation — general behaviour of the part class: a single-chip phoneme-based formant speech synthesizer that builds arbitrary speech from phoneme codes and exposes some control over pitch, amplitude, and rate. Describes what such a device is, not an undocumented claim about the HERO 2000’s particular board.
- ET-19 Technical Manual / Programming Manual (factory primaries; CHM catalogs them) — the authoritative resolution of the SSI 263A / “SPA-256” naming, the speech-subsystem parts list, the catalogue of sound effects, the text-to-phoneme algorithm, and the exact speech call syntax. Cited as the primary a reader consults; the details this volume leaves unclaimed live here.
- HERO 1 and HERO Jr speech volumes (this hub) — the Votrax SC-01 phoneme-stream approach the HERO 2000’s direct text-to-speech is contrasted against; the general formant-synthesis explanation common to phoneme synthesizers of this class.
Comments (0)