Heathkit HERO 1 (ET-18) · Volume 6
Speech — The Votrax SC-01 Voice
6.1 What the speech option was
The HERO 1 could be given a voice. Speech was not part of the base machine; it
arrived as an optional accessory, the ET-18-2 speech board, built around the
Votrax SC-01 phoneme speech synthesizer, and on the kit it carried its own
price — roughly $149.95 added to the build (Wikipedia, “HERO (robot)”;
hero.dsavage.net HERO FAQ). When fitted, the robot could speak under program
control: the announcement at the end of a sensing-and-acting routine, the spoken
status that turned a silent demonstration into a talking one. The voice was part
of what made the HERO 1 read, to a 1982 audience, as a robot rather than a
rolling microcontroller.
This volume covers what that option was and, in depth, how the chip behind it turned a stream of small numeric codes into continuous English speech. The HERO-specific facts — that the option existed, what it was built on, what accompanied it — are gated to the HERO record (Wikipedia, the HERO FAQ, and the ET-18-2 speech-board manual in the factory manual set). The general behaviour of the Votrax SC-01 is attributed to the SC-01’s own documentation; where this volume describes the chip’s internals it is describing the part, not making an undocumented claim about the HERO 1’s particular board.
6.2 Two ways to make a robot talk
There are two broad ways to give a machine a voice, and the distinction explains why the SC-01 mattered.
The first is stored-word playback: record (or otherwise capture) a fixed set of whole words or phrases as digitized audio, store them, and play them back on cue. This is simple and the result sounds exactly as good as the recording — but the machine can only ever say the words that were stored, the storage cost grows with every word added, and the vocabulary is frozen at manufacture. A robot built this way has a closed dictionary; teaching it a new word means storing new audio.
The second is synthesis from sub-word units — building speech from pieces smaller than a word. The Votrax SC-01 takes the most economical version of this approach: it synthesizes from phonemes, the elementary sounds of speech. An English utterance decomposes into a few dozen distinct phonemes; string the right phonemes together in the right order and you get any word, including words no one anticipated. The cost is not per-word storage but the much smaller, fixed cost of the phoneme set built into the chip, plus a short code stream per utterance. The trade is intelligibility and naturalness: phoneme synthesis of this era has the characteristic flat, buzzy, slightly robotic timbre rather than a recorded human voice. For a teaching robot whose whole point was open-ended experimentation, the open vocabulary of phoneme synthesis was the right trade (general behaviour per Votrax SC-01 documentation).
6.3 The Votrax SC-01, in detail
The SC-01 is a single-chip phoneme-based formant speech synthesizer: a CMOS integrated circuit that accepts a code selecting one phoneme at a time and produces the corresponding speech sound on an analog output, continuously, as the codes are fed to it (Votrax SC-01 documentation). It is the part that made affordable open-vocabulary speech practical for early-1980s consumer hardware, and the same chip — and its later SC-01A revision, a ROM-tweaked version with improved synthesis quality — turns up across the period in arcade machines and hobby add-ons as well as in the HERO 1’s speech option (Votrax SC-01 documentation).
6.3.1 The phoneme set and its codes
The SC-01 carries a fixed repertoire of 64 phonemes, each selected by a 6-bit phoneme code (six bits address 2⁶ = 64 values, so the code space and the phoneme set match exactly). The phoneme symbols are a modified form of the ARPAbet phonetic alphabet — the standard scheme for writing English sounds as short letter codes — so that, for example, distinct codes select the consonant and vowel sounds that spell out a word. To make the chip say something, software presents one 6-bit code, lets the chip render that phoneme, then presents the next: speech is the chip working through a stream of phoneme codes in order (Votrax SC-01 documentation).
Because each utterance is just a short list of small numbers, the data rate is modest — the SC-01’s documentation gives a figure on the order of 70 bits per second for continuous speech, which is why a slow 8-bit host can keep the chip fed without difficulty (Votrax SC-01 documentation). This is the structural opposite of stored-word audio: a sentence is described, not recorded.
6.3.2 How formant synthesis builds the sound
What the chip does with each code is the interesting part. Human speech sounds are shaped by formants — the resonant peaks the vocal tract imposes on the sound produced by the vocal cords. Each vowel and voiced sound has a characteristic pattern of formant frequencies; the ear identifies the sound largely from where those resonant peaks fall. A formant synthesizer does not store any recording of a voice. Instead it generates sound from scratch with a model of the vocal tract: an excitation source — a buzzy periodic waveform standing in for the vocal cords (for voiced sounds like vowels) or a noise source (for unvoiced sounds like s and f) — passed through a bank of filters tuned to the formant frequencies of the target phoneme (Votrax SC-01 documentation).
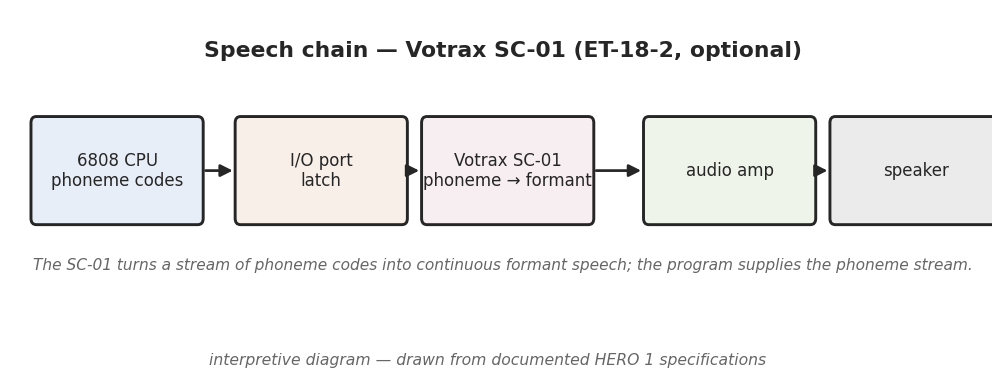
Inside the SC-01, the incoming 6-bit code selects, from the chip’s internal data, the set of filter and timing parameters that define that phoneme — which formant frequencies, which excitation type, what duration. A phoneme-construction algorithm and the chip’s filters then synthesize the corresponding segment of audio (Votrax SC-01 documentation). Crucially, the chip does not snap abruptly from one phoneme’s parameters to the next: it transitions between successive phonemes’ formant targets so the segments run together into a connected sound. That gliding between formant targets is what makes a string of discrete codes come out as continuous speech rather than a sequence of isolated beeps — and it is also the source of the characteristic Votrax timbre. The diagram in Figure 1 traces this chain: code stream in, per-phoneme formant rendering, continuous audio out.
6.3.3 Inflection — a little prosody
A flat monotone is the giveaway of cheap synthesis, so the SC-01 provides a small amount of prosodic control. Beyond the 6-bit phoneme selection, the chip accepts inflection bits giving four levels of intonation (pitch), so a program can raise or lower the pitch of a phoneme — enough to put a rising contour on a question or a falling one on a statement, even if the result is far from natural human prosody (Votrax SC-01 documentation). Pitch control on the SC-01 is coarse — four steps, not a continuous contour — but it is the difference between a dead monotone and speech with at least the suggestion of melody.
6.4 Driving it from a HERO 1 program
On the HERO 1 the speech option was not a sound the operator triggered by hand; it was something a program produced. The robot’s job, when speaking, was to put the right phoneme codes in front of the SC-01 in the right order and at the right moments — exactly the stream-of-codes model above, with the HERO 1’s Motorola 6808 as the source of the stream. Producing speech therefore meant translating the intended words into their phoneme codes and writing those codes out to the speech board, code after code, letting the chip render each before sending the next. The broader subject of how a HERO 1 program was written and run — machine code from the hex keypad, HERO-1 BASIC via the expansion ROM, the teaching pendant, the remote and host links — is the territory of Vol. 7; this volume’s concern is only the last link, the codes reaching the SC-01.
To make that translation tractable for the programmer, the speech option shipped with a voice dictionary — documented reference material, accompanying the ET-18-2 speech board, that mapped words and sounds to the phoneme codes needed to produce them, so a builder could look up how to spell a word for the synthesizer rather than work out its phonemes unaided (HERO FAQ; ET-18-2 speech-board manual). The exact extent of that dictionary — how many words it tabulated — is not established here, and no specific vocabulary or word count is claimed for the HERO 1’s speech option; what is documented is that a phoneme/voice dictionary accompanied the board (Wikipedia; HERO FAQ). What the chip could ultimately say was, in principle, open-ended: any utterance the programmer could spell in phonemes, which is the whole advantage of synthesis over stored playback.
6.5 Where the SC-01 sat in early-80s consumer speech
The SC-01’s significance is best seen against its moment. At the start of the 1980s synthetic speech was newly affordable to consumer products, and a handful of single-chip synthesizers defined what a talking machine could be. Phoneme formant synthesis of the SC-01’s kind was the route that bought open vocabulary cheaply — the machine was not limited to a fixed list of recorded words, at the cost of that distinctive synthetic timbre (Votrax SC-01 documentation). For Heathkit’s purposes that trade was ideal: a teaching robot is a platform for experiments nobody scripted in advance, and a closed dictionary of stored words would have been a poor fit for a machine whose value was open-ended programmability. Giving the HERO 1 a Votrax voice meant the student’s own program decided what the robot said, one phoneme at a time.
For the reader who wants the rest of the robot around this voice: the 6808 and bus that fed the codes are in Vol. 2; the head that carried the speaker and sensors and the body that housed the board are in Vols. 3–4; the sensing the robot might announce — sonar range, a detected sound or motion — is in Vol. 5; and the programming routes that actually drove the SC-01 are in Vol. 7. Every hard speech fact in this volume is collected, with the rest of the machine’s numbers, in the Vol. 9 cheatsheet.
Sources
- Wikipedia, “HERO (robot)” — the Votrax SC-01 as the HERO 1’s optional speech synthesizer; the ~$149.95 kit price for the speech option; that a voice/phoneme dictionary accompanied it.
- HERO FAQ (
hero.dsavage.net) — the speech option as the ET-18-2 board built on the Votrax SC-01; accessory/part-number record. - ET-18-2 speech-board manual (in the factory ET-18 manual set on the Internet Archive) — the authoritative primary for the HERO 1’s speech board and its voice dictionary; consult it for the exact code tables and the dictionary’s extent.
- Votrax SC-01 documentation — general behaviour of the part: a phoneme-based CMOS formant speech synthesizer producing continuous speech from a stream of 6-bit phoneme codes; 64 phonemes (modified ARPAbet); four levels of intonation; the SC-01A revision; the order-of-70-bits-per-second data rate.
Comments (0)